python实战003:Selenium模拟浏览器获取网页源码
1、使用Selenium需要浏览器驱动配合,如何下载可以参考:python实战001:模拟浏览器操作准备工作,这里我使用的是chrome浏览器,下载chrome webdriver 放到python的安装目录即可。

2、Selenium访问页面 首先我们需要先引入Selenium中的webdriver对象,定义一个具体browser对象(这里我使用的是Chrome浏览器),通过get方法即可打开制定的网址了。
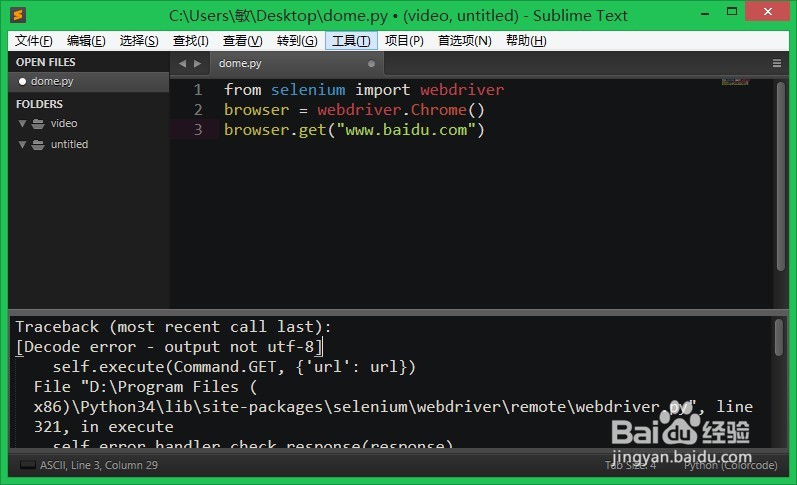
3、这里编译的时候出现错虱忪招莫误,Sublime提示[Decode error - output not utf-8] 错误,意思是[解码错误-输出不是UTF-8]。这时我们就要修改Sublime Text的python 编译系统的设置。将其编码设置为cp936。打开Python.sublime-build文件,在尾部添加一行"encoding":"cp936"这一行,保存即可解决这个问题。

4、继续编译,有出现了未知错误unhandled inspector error: {"code":-32000,"message":"Cannot navigate to invalid URL"}翻译:未处理的检查器错误:“code”:-32000,“message”:“无法导航到无效的url”,这里将网址写全即可。

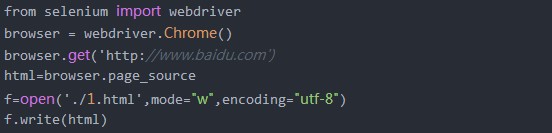
5、如果想获取网页源代码,这时我们可以使用page_source方法,这时我们就可以在后台获取到该网页的源码,输出时别忘了指定编码格式utf8,否则会报输出格式错误。from selenium import webdriverbrowser = webdriver.Chrome()browser.get('http://www.baidu.com')html=browser.page_sourceprint(html.encode("utf8"))

6、为了更好的查看源码内容,这时可以借用python的open方法,将获取到的网页源码写入到html文件中,这样方便查看内容,通过以下代码我们在当前目录下生成一个1.htnl文件并将源码写入到该文件中。